
⏹️⏹️⏹️⏹️⏹️⏹️⏹️⏹️⏹️⏹️⏹️⏹️⏹️⏹️⏹️⏹️⏹️⏹️⏹️⏹️⏹️⏹️⏹️
Ratio Scales, Definition, Examples, and Data Analysis
- A ratio scale is quantitative with true zero and equal intervals between neighboring points.
- A ratio scale of zero means a total absence of the variable you are measuring.
- An interval scale does not have any of the above mentions.
- Length, area, and population are examples of ratio scales.
- The ratio level contains all of the features of the other 3 levels.
- At the ratio level, values can be categorized, and ordered, have equal intervals, and take on a true zero.
- Nominal and ordinal variables are categorical variables
- Interval and Ratio variables are quantitative variables
- Many more statistical tests can be performed on quantitative than categorical data
So What is a True Zero?? 🟥🟥🟥🟥🟥🟥🟥
- On a ratio scale, a zero means there's a total absence of the variable of interest.
- For example, the number of children in a household or years of work experience are ratio variables.
- A respondent can have no children in their household or zero years of work experience.
- With a true zero in your scale, you can calculate ratios of values.
- For example, you can say that 4 children are twice as many as 2 children in a household and eight years is double 4 years of experience
- Some variables, such as temperature, can be measured on different scales
- Celcius and Fahrenheit are interval scales
- Kelvin is a ratio scale
- In all three scales, there are equal intervals between neighboring points
- The Kelvin scale has a true zero, where nothing can be colder.
- That means that you can only calculate ratios of temperatures in the Kelvin scale
- A true zero makes it possible to multiply, divide, or square root values.
- Collecting data on a ratio level is always preferable to the other levels because it is the most precise.
Examples of ratio scales ⏹️⏹️⏹️⏹️⏹️⏹️⏹️
- Interval variables and ratio variables can be discrete or continuous.
- A discrete variable is expressed only in countable numbers
- A continuous variable can potentially take on an infinite number of values.

- Number of vehicles owned in the last 10 years discrete
- The number of people in a household discrete
- The number of students who identify as religious discrete
- reaction time in a computer task continuous
- Years of work experience continuous
- Speed in miles per hour continuous

🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥
Ratio Data Analysis
- After you have collected ratio data, then you can gather descriptive and inferential statistics
- Almost all statistical tests can be performed on ratio data because all mathematical operations are permissible
- Ratio data example - you collect data on the commute duration of employees in a large city
- the data is continuous and in minutes
- To summarize your data, you can collect the following descriptive statistics :
- the frequency distribution in numbers or percentages
- the mode, median, or mean to find the central tendency
- the range, standard deviation, and variance to indicate the variability
- You can get an overview of the frequency of different values in a table and visualize their distribution in a graph

- Enter your data into a grouped frequency distribution table.
- Create groups with equal intervals on the left-hand column and enter the number of scores that fall within each interval into the right-hand column.

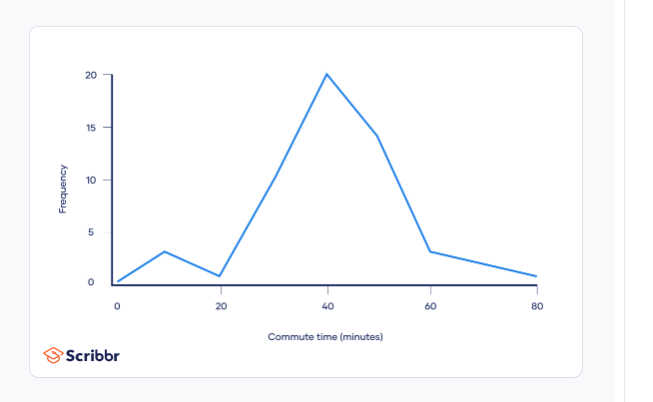
- To visualize the data, plot it on a frequency distribution polygon.
- Plot the groupings on the x-axis and the frequencies on the y-axis
- Join the midpoint of each grouping using lines
- The range, standard deviation and variance describe how spread your data is.
- The range is the easiest to compute
- The standard deviation and the variance describe how spread your data is and they are also more informative.
- The coefficient of variation is a measure of spread that only applies to ratio variables
Range
- To find the range subtract the lowest value from the highest value in your data set.
- the range equals72.5 - 7 = 65.5
Statistical Tests
- With a normal distribution of ratio data then parametric tests are best for testing hypotheses
- Parametric tests are more powerful than non-parametric tests and you can make stronger conclusions with your data
- The data must meet several requirements for parametric tests to apply
- The following chart lists parametric tests that are some of the most common ones applied to test hypotheses about ratio data

🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥
References
Bhandari, P. (2020, August 28). Ratio Scales | Definition, Examples, & Data Analysis. Scribbr. https://www.scribbr.com/statistics/ratio-data/




















